
 CloudAve readers can now follow the contributing bloggers’ twitter stream in a sidebar, thanks to a cool widget called Tweet Blender. Finding it was not easy: I combed through at least 100 plugins / widgets, all doing essentially the same: follow a person, or do keyword search. Either or.. not both. And definitely not a selection of users.
CloudAve readers can now follow the contributing bloggers’ twitter stream in a sidebar, thanks to a cool widget called Tweet Blender. Finding it was not easy: I combed through at least 100 plugins / widgets, all doing essentially the same: follow a person, or do keyword search. Either or.. not both. And definitely not a selection of users.
Tweet Blender came to the rescue (before Twitter Lists): it allows to follow any combination of users and keyword searches. Smart! But just days after I installed it along came Twitter Lists … so the writing for Blender was on the wall.
Not until Lists got supported in widgets though.. which is what we’re seeing today. Twitter introduced their List Widget. I quickly replaced Tweet Blender with the new widget, if only for testing at Enterprise Irregulars, another group blog I am editing, thinking it might help with a major problem I have with Twitter API limits.
Here’s the gist of the problem: Every time the widget refreshes, it eats into my API allocation – and it bites big: one API acces per user followed. Over at Enterprise Irregulars we have thirty or so authors on Twitter, so 5 refreshes and I am out of luck (and API). But the author of Tweet Blender came up with a smart caching solution, turning all blog readers into API contributors:
As of this writing, Twitter allows only 150 connections per hour from a single IP address.
Since TweetBlender works in user’s browser, this means 150 connections from the user viewing the page on your site.
For each screen name in the list of sources there is one connection made. For hashtags and keywords, they all bunched into one search query and only 1 connection is made.
This means: if you have 30 screen names – every update makes 30 connections; if you have 30 hashtags – every refresh makes 1 connection. If you have 30 screen names AND 30 hashatags – every request makes 31 connection.
If you set TweetBlender to refresh every 10 seconds and you have 50 screen names in sources then after the 3rd refresh the user viewing the page would reach the connection limit – i.e. in 30 seconds they will be done and would have to wait for 59 minutes and 30 more seconds before fresh tweets become available.
The more screen names you have – the quicker the limit is reached.
To deal with it, caching is added. When user A gets fresh tweets in his browser they are sent to your server and stored there. When user B gets fresh tweets in his browser (against his own 150 limit) they are also updated on the server. All users that view your page keep the cache fresh.
Once user A reaches his limit TweetBlender switches to cached mode and instead of going directly to Twitter, starts getting tweets from your server. If user B is not yet at the limit then his updates will help user A see fresh content.
The more users view your page and the more evenly the traffic is spread out – the less chances of reaching the limit. All visitors to your site will keep cache up to date and help each other
An absolutely smart solution – but what if I don’t have the API problem at all? This is what I expected to test with Twitter’s own solution. But what disappointment… If you look at Enterprise Irregulars, you probably see the tweet stream – I don’t. All I see is a blank frame. Sam on Scoble’s blog. Or Mashable. Or Brian Solis.
I’m out of Twitter API allocation (or so I assume – could not confirm yet). But while Tweet Blender uses a cache, in fact a collaborative smart cache, Twitter’s own Widget just throws up. Yuck. Tweet Blender is the absolute winner. For now.
I’m writing this post as a tribute to Kirill, Tweet Blender’s developer, also in recognition of his outstanding responsivenes. Read the Facebook threads – he investigates individual installations, comes up with bug fixes overnight – exemplary Customer Service from a one-person team.
But he has just become endangered species. With gazillion $ in funding Twitter has the resources, and will no doubt come up with a solution to the API / caching problem. But let’s not write the little guy off just yet: his product still has more / better features… and I have no reason to believe he will sleep on his laurels. 🙂
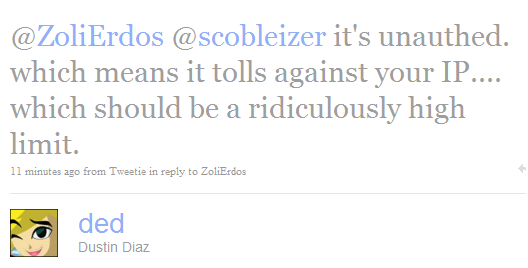
Update: my assumptions just got confirmed:

(Cross-posted @ CloudAve )

Recent Comments