
In case you’re wondering, I’m talking about Twitter. Their blog-post addressing system failures is outright shocking.
We’ve gone through our various databases, caches, web servers, daemons, and despite some increased traffic activity across the board, all systems are running nominally. The truth is we’re not sure what’s happening.
Translation: sorry everyone, we have a popular service and have no clue why it’s constantly crashing. It’s bad. really-really bad. But hey, at least they are honest. And the $15 million they’ve just picked up should be enough to hire someone who actually knows how to get out of this mess. (Update: they just did)
Update: On second thought, I am less optimistic forgiving. Twitter already raised $5M before this round, that should have allowed them to bring in expertise they clearly lack. If only their priorities were on fixing the service instead of chasing more money.
I keep on re-reading the blog post:
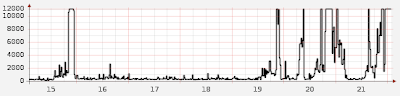
I have this graph up on my screen all the time.
So what? Here’s the chart I often check, provided by Zoho’s Site24x7 service:
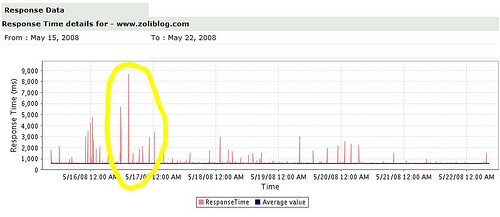
I have no idea where the spikes (performance degradation) come from. I’m just as clueless as the twitter team. The difference: I’m not providing a service people became dependent on.


There can’t be too many scenarios of what’s happening.
1. the caching system is not designed very well, and it’s possible that right at the moment of cache building their systems are overloaded with requests
2. someone is flooding them with fake requests
It’s really strange how their infrastructure that hosts a pretty simple system (text posting) is not able to handle loads. maybe they should ask facebook hot to run their infrastructure?
The really strange thing about all this is that there hasn’t been a shift to another service that is more stable. Maybe Web 2.0 means we are more forgiving of downtime?