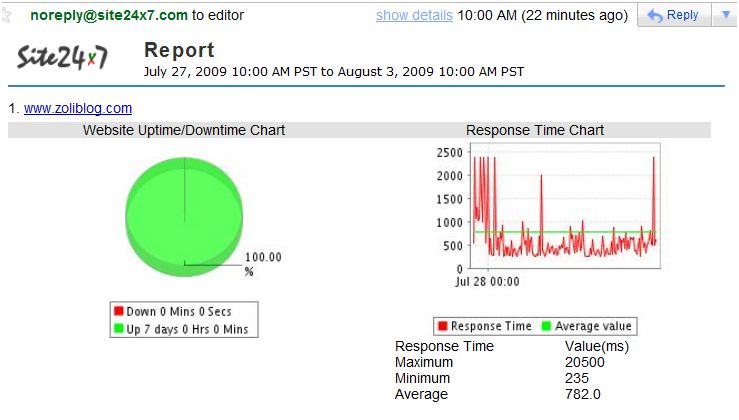
Courtesy of site24x7 by Zoho. Thanks to my host, PressHarbor.
Connecting the dots ...

Courtesy of site24x7 by Zoho. Thanks to my host, PressHarbor.
No service is a 100% available, and of course your SaaS provider’s outage always comes in the ‘worst time’, just when you have a deadline to meet… what really gets painful is when you have no information whatsoever on what just happened and how long the outage may be. Major providers like Salesforce.com and Amazon learned the lesson the hard way, and they both released their status dashboards after extended outages and the customer uproar that followed:
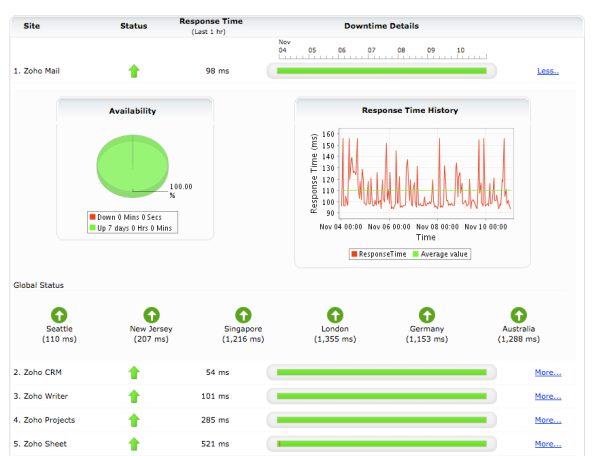
Free services rarely display such level of transparency, but that’s exactly what Zoho is announcing today: they created Zoho Status , a monitoring service which displays the health of all Zoho Applications – currently 24. Here’s a partial screen-print:
![]() If it looks familiar, perhaps you followed my earlier advice on using Zoho’s Site24×7 service on your own site or even blog. I’ve been using it for two years now, and received alerts of outages that neither I nor my service provider were aware of.
If it looks familiar, perhaps you followed my earlier advice on using Zoho’s Site24×7 service on your own site or even blog. I’ve been using it for two years now, and received alerts of outages that neither I nor my service provider were aware of.
Zoho took their own tools and turned it into a public availability display, monitoring their services from six different locations: Seattle, New Jersey, Singapore, London, Germany and Australia. For now the display is rather “boring”, being all green. Obviously we’re all better off if it stays that way and we have no reason to check the status site.
What makes sense, however, is to use Site24×7 on your own site, or on any service you are dependent on (you don’t have to install anything, it’s all external monitoring). As usual, it starts with a free level, adding extra paid services – the new addition today is the Enterprise version, allowing SLA definition, compliance tracking and reporting.
Related articles:
(This article is cross-posted from for CloudAve, the Zoho-sponsored Cloud-Computing / SaaS / Business Blog I am editing. Subscribe to our feed here.)

In case you’re wondering, I’m talking about Twitter. Their blog-post addressing system failures is outright shocking.
We’ve gone through our various databases, caches, web servers, daemons, and despite some increased traffic activity across the board, all systems are running nominally. The truth is we’re not sure what’s happening.
Translation: sorry everyone, we have a popular service and have no clue why it’s constantly crashing. It’s bad. really-really bad. But hey, at least they are honest. And the $15 million they’ve just picked up should be enough to hire someone who actually knows how to get out of this mess. (Update: they just did)
Update: On second thought, I am less optimistic forgiving. Twitter already raised $5M before this round, that should have allowed them to bring in expertise they clearly lack. If only their priorities were on fixing the service instead of chasing more money.
I keep on re-reading the blog post:
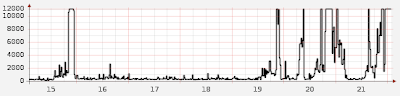
I have this graph up on my screen all the time.
So what? Here’s the chart I often check, provided by Zoho’s Site24x7 service:
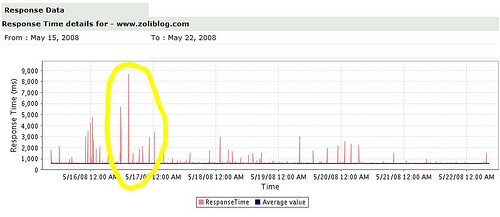
I have no idea where the spikes (performance degradation) come from. I’m just as clueless as the twitter team. The difference: I’m not providing a service people became dependent on.


Publisher / Editor of CloudAve and Enterprise Irregulars.
I do most of my business blogging there, with occasional asides here. More...
Recent Comments